From Hugo to Svelte-Kit
I’ve been spending more time in the last year exploring modern web stacks, and have started evangelizing for SvelteKit, which is a new-ish entry into the often-mystifying world of web frameworks. As of today, I’ve migrated this, personal web site from Hugo, which I’ve been using the last couple years, to sveltekit. Let me know if you encounter any broken links, unexpected behavior, accessibility issues, etc. I figured here I’d give a brief explanation of why sveltekit, and how I did a Hugo-Svelte kit migration.
Why Svelte-Kit for a personal site?
I’ve had some kind of content up at benschmidt.org for over a decade; and I’ve been using it as my primarily outlet for blog posts for about five years (although still posting occasionally on my old blogger site as well. For a time it was hosted on Wordpress; for a time after that, on Hugo. I also have a large number of other items living on benschmidt.org I’ve made over the years that weren’t integrated into the Hugo site; most are things like standalone visualizations that I’d like to be able to retain all their existing javascript but share a top bar with the rest of the site so that people link them to me.
Hugo works find for building compared to wordpress, by giving a static site solution that unlike Wordpress doesn’t present security vulnerabilities. I like, compared to Jekyll, that it’s a quick build. But left me with a somewhat clunky set of pages for things like a visualizations gallery. And although I picked a decent theme–Hugo Academic–I never fully got on board with the weird way that you basically end up having to learn to manage Hugo’s build process through a set of TOML and YAML files. I saw someone once decry the growing trend to make people do things in YAML that are fundamentally programming; although yaml is great for some things, learning the configuration setting for some particular theme is generally frustrating.
Also, the pile-up of all these old web sites means the URL requirements are a little finicky–I want to support some of the old wordpress links, some of the Hugo-style links, and potentially bring in some blog posts for other domains (bookworm.benschmidt.org, for instance, which had a number of posts that I’ve entirely lost.)
So here are the problems that Svelte-kit solves.
Routing. I never really figured out the URL setup for blog posts in the Academic theme for Hugo; and I have a number of old posts from a Hakyll setup I breifly explored in 2015-2017 before abandoning it. Svelte-kit’s routing is incredibly powerful but also fundamentally understandable; every foldername on your computer is a directory in the url structure,
index.sveltefiles turn into the base names, and you can use brackets like/post/[postname]/index.svelteto define dynamic variables where/postnameis the filename. So right now, I’m writing a markdown file at located at2022-01-20-sveltekit-transition/index.md, and checking in a browser window to make sure that the local version is correctly showing images and styles.Image Components. This is a big one for me. For instance, I want to have a gallery where I can just show visuals that will show a tile of images. And since it’s the 2020s, that needs to look one way on desktop and quite a different way on mobile.
Desktop view
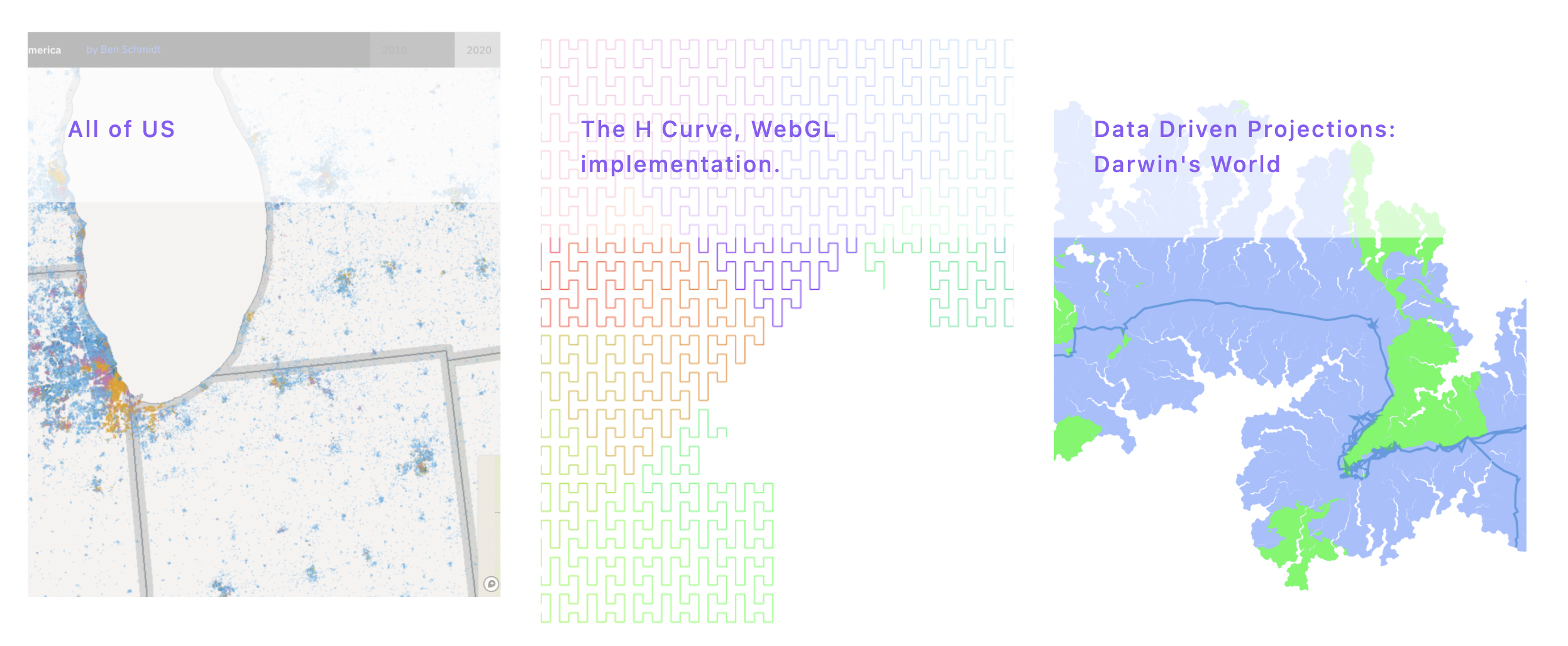
Mobile view
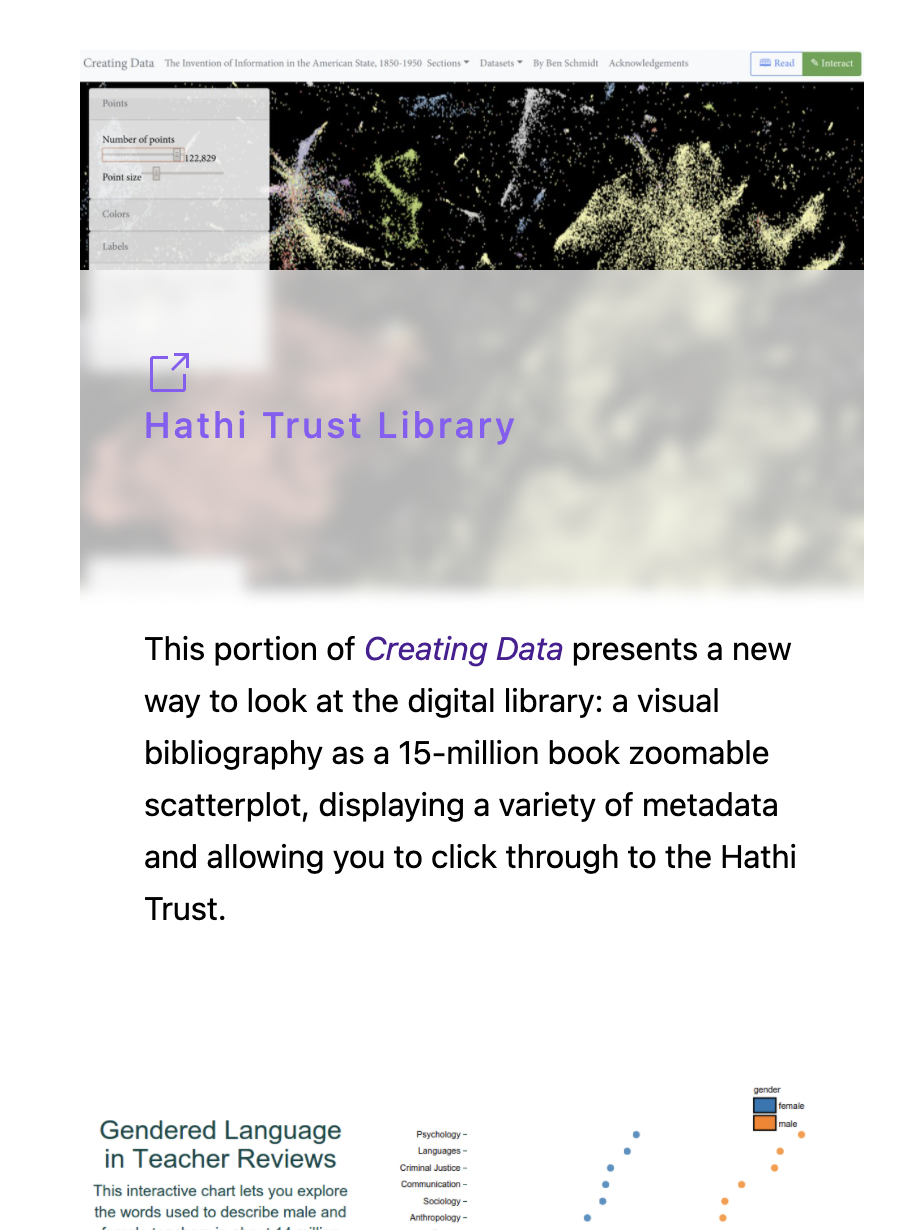
Data Components. I liked how Hugo Academic included a lot of basics for showing carousels of things like articles, but they were never quite what I wanted. And for years I’ve been making my CV using Kieran Healy’s template but compiled from yaml because yuck, latex is gross. That meant I was keeping up two different versions of pretty much the same data, which is a pain. With Svelte, I can just directly import the YAML to the CV page and format the data. For the time being, the online version is a little wonky because it’s sort of a pain to iterate through. But it also means that I can easily abstract something like “upcoming talks” if I ever get it together enough to start handling talk invitations again. I can automatically have the website update the courses I’ve taught from the same file as the CV, with links to the course pages. Etc.
CSS and themes. CSS is incredibly powerful, and incredibly hard to use with most frameworks I’ve explored. One reason is that the CSS gets shunted off into some file somewhere called ‘ /lib/app.scss ’ or something and it’s never clear from the css which things are boilerplate, which are essential classes used everywhere, and which are not used on a site at all. Svelte natively solves this by allowing all components to have a style block at the bottom, scoped just to that file, so I can immediately understand the implications of editing a block. This is especially useful for someone like me who doesn’t think much about colors but occasionally gets finicky about item placement.
It also works well alongside the tailwind CSS (non-)framework, which I’ve been using a bunch lately when I know basically what I want to do but don’t want to think about how to define media queries. It provides a bunch of classes.
Integrating non-blog-content. I have a lot of stuff hosted on benschmidt.org that doesn’t have the theming from my personal website, and I periodically toss other things on. For instance, last week I wanted to share a seminar paper I wrote in grad school about the early years of the academic field of communications. Because I think putting this up will marginally increase the overall quality of the Internet, I just threw it up; and by running it through pandoc from the initial
.docfiles to HTML, I can just toss it into a folder and have it show up with formatting and links to my page. This would probably have worked in Hugo too; but as I start to incorporate some more elaborate javascript visualizations here, that will be harder and harder, at least without massively duplicating some common code libraries.Static serving with dynamic speed. One of the things that drew me to Svelte and Svelte-kit immediately is their possibilities for static-site set-ups. Fancy web apps are fun–I have one for creating an archive I’ll put out later–but I have a hard requirement that sites should be able work indefinitely without javascript at least in some form. Svelte-kit with adapter-static does a wonderful job splitting the difference here, making an initial page load always land on a real, static site file but also allowing site navigation to not refresh all the shared elements on a page if Javascript is enabled.
Hugo to Svelte-Kit
The last, and maybe most important, is that migration be possible. For anyone else looking to switch, here are some Hugo-to-Sveltekit migration notes.
Blog posts have got to stay in Markdown. I just chose to shove most of the contents of the Hugo tree into ‘ src/content ’, to live alongside ‘ src/lib ’ (which is for code) and ‘ src/routes ’. It would also be possible to put posts into
src/routesdirectly and use a markdown plugin to generate sites straight from the Markdown. I chose not to do this because at least in my preliminary exploration, svelte was trying to treat all{}blocks as interpolatable, which isn’t what I want. Most of the hard work then happens in a markdown parsing file that just globs up all the markdown in that directory and parses it into HTML (and the YAML headers as JSON) usingvite-plugin-markdown. This requires a little tinkering with thesvelte.config.jsfile.
const urls = import.meta.globEager('/src/content/**/*.md');
The result is then an export that I can use on any page that contains the metadata for all blogposts as data in reverse-chronological order; although the actual code has to do more to handle tag-based navigation, the skeleton of the the page is basically only this:
<script>
import {post_index} from '$lib/markdown.ts'
import Postgroup from '$lib/components/Postgroup.svelte'
</script>
<Postgroup posts={post_index} />
So now I have canonical URLS for posts at /post/slugname/, without year and month as part of a tree. All the messy old urls are still supported, though, by alternate routing endpoints that just comb through the metadata for those posts to try to determine what you’re looking for. This is unlikely to catch everything at first, but I can comb through server logs to see I’m contributing to link rot and easily set up new rules.
Non-blog pages are routed through a catchall endpoint that just finds the matching markdown file and compiles it. Easy-peasy. For the pages where I want to start doing something more complicated or data-driven, like the blog index, the dataviz gallery, or the CV, I write a custom Svelte component or page.
There’s something kind of lovely about the basicness of all this on the core level. If I want a blog feed–yes, I do!–I just define a route at /index.xml that throws back something from whatever node package I can find that generates atom XML.
Is this flawless? Definitely not–I’ve sure there will be plenty of broken likes soon. But I’m hopefully it will give me a nicer platform to bundle stuff together onto the Web. And as I’ve become even more evangelical about web publishing during this pandemic, that’s important to me.