Digital Collections, Research Libraries, Collaboration
[The following is a revised version of my talk on the ‘ collaboration ’ panel at a conference about “Needs and Opportunities for the Research Library in the Digital Age” at the American Antiquarian Society in Worcester last week. Thanks to Paul Erickson for the invitation to attend, and everyone there for a fascinating weekend.]
As a few people here have suggested, there’s a lot to be suspicious of in the foisting of collaboration on unsuspecting researchers. To those worries about collaboration that have already been brought up (including by myself elsewhere), I’d add the particular suspicions that early-career scholars often bear. Collaboration is often one of those ambitious things that successful scholars only seem to turn to in earnest with the security of tenure, like transnational history or raising children.
But in the last few years, I’ve turned more and more to working with digital sources; and in doing so, it turns out collaboration is essential. It’s impossible to escape. And, as everyone says, it really is wonderful.
But the forms that digital collaboration takes, particularly when it’s most helpful, are very different than the traditional forms of heady engagement around a shared codex, blackboard, or meal that tend to get us most sentimental when talking about collaborative work. And that has important implications for libraries like this, because it suggests that the way you find your collaborators may be quite different. In some cases, you may not even know who they are. And the attributes it takes to attract these invisible collaborators can be quite different from those that libraries traditionally try to display, though they remain one that a library like this may have in abundance.
1. Bookworm Background
So I want to sketch out the role that collaboration can play for scholars working around digital sources, particularly on the Bookworm project that I’ve worked with at the Cultural Observatory. To explain that project, I want to make a bit of detour about where I see the scholarship in my own field, American cultural/intellectual history, at present. For while I identify as a digital historian, the fact is that at this point, everyone is using some of the most sophisticated text-mining algorithms ever developed in their daily research; that’s what search engines are.
In American history, this has led to an efflorescence of excellent and influential studies of broad conceptual topics–histories of risk or public opinion, and targeted tracking of the diffusion of individual thinkers like Nietzsche or Heidegger. But the current execution of such projects does (or should) rely heavily on digital sources, accessed through keyword searches.
But while keyword search is good for certain purposes (tracking down a particular text, finding a book to sell), it’s far from ideal for real historical research. It gives no sense of the scale of the libraries we are looking at–which, for research purposes, is one of their most salient characteristics. This loses the sense of scale or importance that one can get in physical libraries–one knows just how hard it is to locate a particular needle in a particular haystack, and has a sense of just how unlikely that particular needle might be. In digital libraries, the ordered list is all we see. It’s as if we’re recreating the closed-stack library for the digital age–only one book comes, and you never know how or whence.
We currently treat all the books not returned in a keyword search as detritus; we need to treat them as context.
What does context look like? I would argue that working with digital texts, “context” and “data” are going to look pretty similar. And that’s how I got lured into researching digital books.
But when the line between ‘ context ’ and ‘ data ’ gets blurred, something else happens: the scientists start to return to the libraries, after a generation of absence. And this creates a whole raft of opportunities for collaborative and interdisciplinary work. I ended up at Harvard because two scientists, J.B. Michel and Erez Lieberman Aiden, were kind enough to invite me up for a period of time.
Their previous work had culminated in a paper in Science about trends in words. If you know this work, it’s probably because of the supplemental materials, particularly the Google Ngrams site launched in December 2010.
The reaction of many humanists to Ngrams is to play with it for a few minutes, and then abandon it in confusion about the meaning of trend like that for “libraries”:
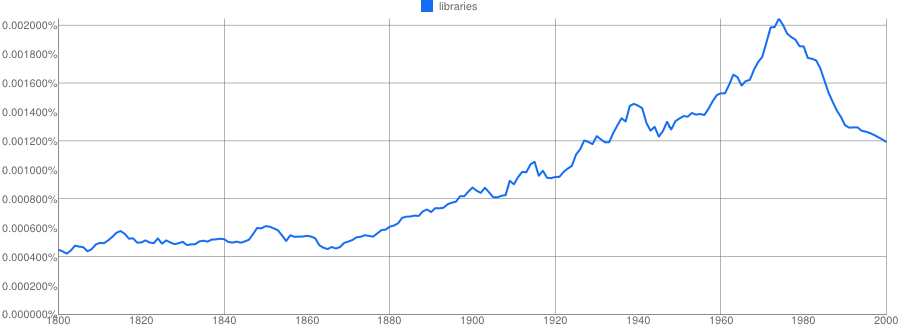
My first message about Ngrams for humanists is generally that the data is considerably more powerful than you think, and can frequently generate useful insights. So for instance, you can look at the relative constellation of words around ‘ libraries ’* to see how they were described–

_--_and probably find something you didn’t know before, or at least reflect on patterns that weren’t clear. (Though you may be familiar with it, I had never heard of ‘ traveling ’ libraries, the blue bump around 1910 in the middle of the chart, and lost about half an hour reading up on their history when I found they existed).
*I didn’t say in Worcester that I settled on ‘ libraries ’ for this example because “library” is an almost impossible term to type into the Ngrams database this way, because of all the bookplates and borrowing slips that were scanned and OCR’ed. Lower-case “library” might have worked.
But Ngrams does have major problems–mostly particularly the limited usefulness of a single text base as a proxy for ‘ culture ’ writ large to the exclusion of specific areas. (Print culture, scientific culture, mass culture, etc), and the lack of access to the individual books included in the sample. Erez, JB, Martin Camacho and I sought to tackle this at the Cultural Observatory last fall. We wanted to make a browser that allows the arbitrary creation of charts for any subfield the user might want; the Digital Public Library of America had a Beta Sprint project that provided a useful impetus to rethink Ngrams more along the lines of a library interface.
This meant we needed a new source of books. Google’s are heavily encumbered by copyright restrictions–moreover, even the metadata is off limits because of licensing agreements. We ended up choosing instead choosing the Internet Archive instead.
Since this conference is about independent research libraries, I want to note that the IA is absolutely one of those, though it’s not as old as the Newberry or the Folger–though I don’t have anything at stake, I’d love to see it join the IRLA.
We chose the IA for the DPLA Beta Sprint Bookworm for three major reasons:
They allowed free downloads of text files of scanned books.
They had worked through a subproject, the Open Library, to gather metadata primarily from libraries that was available under a public license and linked to those books.
Both of these were exposed through well documented public APIs with well structured and fairly consistent metadata.
But this had a curious result: when Martin and I were downloading books from the IA, they didn’t know we were doing it. (Maybe they saw a million curl requests from Cambridge in two or three days, but maybe not.)
But nonetheless,we were able to build something that met our needs for internal research (which I won’t talk about here), and moreover, that _drove access back to them–_the read links when you click on the lines in Bookworm direct you back to the Internet Archive itself, and the book reader they developed.
2. Quality, not Quantity.
You may be wondering what this has to do with smaller libraries: after all these, most of the sources we’ve worked with have been concerned with the big picture–some ambition to get all the books.
The answer, I think, is that the day is probably coming fairly soon–if it’s not already here–when there will be a single source to go to for published books. If you believe in market solutions, that will be Google; if you believe in the university research complex, it will be Hathi; if you believe in the anarchic potential of the open web, it will be the Open Library or maybe the DPLA.
But you can only answer so many questions with books. Our latest project with Bookworm, released last week, was based around an entirely different collection–arxiv.org, a collection of hundreds of thousands of scientific preprints maintained by the Cornell libraries, which gives an incredibly comprehensive view of research in several specific fields of math and physics. The other collections we’re looking into now are primarily much like this: they are comprehensive in their own way, but don’t have the totalizing ambitions of Google or Hathi. Instead, they share a set of attributes with them:
Well cultivated collections
Strong in a particular area of focus
High quality metadata
Metadata particular to the set, giving some attribute (gender, location, particular scientific discipline) that is unavailable from other standpoints
APIs and licensing agreements that enable open access
These are the sorts of collections that are going to be interesting to those looking to think of large collections of texts in the hybrid realm between data and words, and which can help drive more use of the collections.
Except for the last point, these are all attributes that many independent and university collections have in abundance.
There’s a sense sometimes that if a library scans all its collections and gives them away, it will have nothing more to offer. Aside from the obvious objections (the project of perfectly digitizing physical objects will never be complete), this misses something important; the chief asset of many libraries with relation to their holdings is the metadata about them. A digital object still has a home.
If a library creates a digital home for an object, it will likely be the place that all future uses of that object come back to. (In most cases, no one will be interested in taking away the right to provide a web presence for a particular manuscript or artifact–and if the originators catalog changes, that will take priority for all future uses.). And the curatorial expertise around those objects make the original holder an important repository; there needs to be someone who knows the flaws or biases of a collection or a catalog. But it is equally important for libraries to know the opportunities and uniqueness of their collections as well. There’s sometimes a sense in the digital humanities community that linked open data will appear in a blur of RDF triples and obliterate the need for separate standards. Perhaps this will come, but I don’t think it’s soon–and in any case, it’s the particularities of their collections–the bits that are hardest to stuff into a Dublin Core field–that may be the most useful to researchers working with large quantities.
Comments:
Ben, great talk. The flip side of this is insuring…
Ellen Fernandez-Sacco - Apr 2, 2012
Ben, great talk. The flip side of this is insuring that support (material & financial) for libraries exists across a wide institutional spectrum, and for further development of projects like the Internet Archive. Interdisciplinary collaboration is so important, and it remains an important role for the library, whether local or institutional.