Isms and ists
Nov 15 2010
Hank asked for a couple of charts in the comments, so I thought I’d oblige. Since I’m starting to feel they’re better at tracking the permeation of concepts, we’ll use appearances per 1000 books as the y axis:

And Darwin after the break.
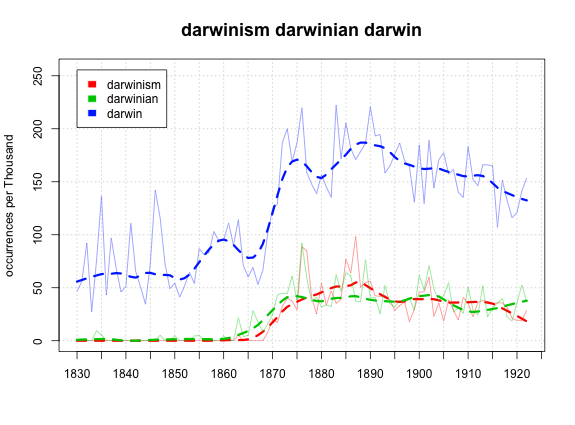
Comments:
Good stuff, Ben. I want “Darwinist,” for…
Hank - Nov 5, 2010
Good stuff, Ben. I want “Darwinist,” for the record, on the last one. Any chance? Also, any way to tell whether things like “Darwinism” are getting mention more in natural-sciences works or elsewhere? Maybe by finding linked words (before you get your “genre” thing up and running)?
Been meaning to comment–“darwinist” is …
Ben - Dec 1, 2010
Been meaning to comment–“darwinist” is very rare, and didn’t make my initial cut. There are 3922 occurrences of ‘ darwinism ’ in the data set, and just 84 of ‘ darwinist ’ and ‘ darwinists ’ combined. So whatever the numbers are, they’re going to be tiny compared to the others. (I’d put them up, but I have to fix a few things in the database before it works again.)